一、技术背景与动机
在自然语言处理领域,基于Transformer的大语言模型(LLM)在生成较长序列时,传统Attention机制的时间复杂度会急剧上升。算法原理上,每生成一个新Token都需要与前面所有Token计算相关性,导致时间复杂度达到O(n²):
$P(x_{n+1} \mid x_1, \dots, x_n) \propto \exp\left( \frac{Q_{n+1} \cdot K_j}{\sqrt{d_k}} \right), \quad j=1,\dots,n$
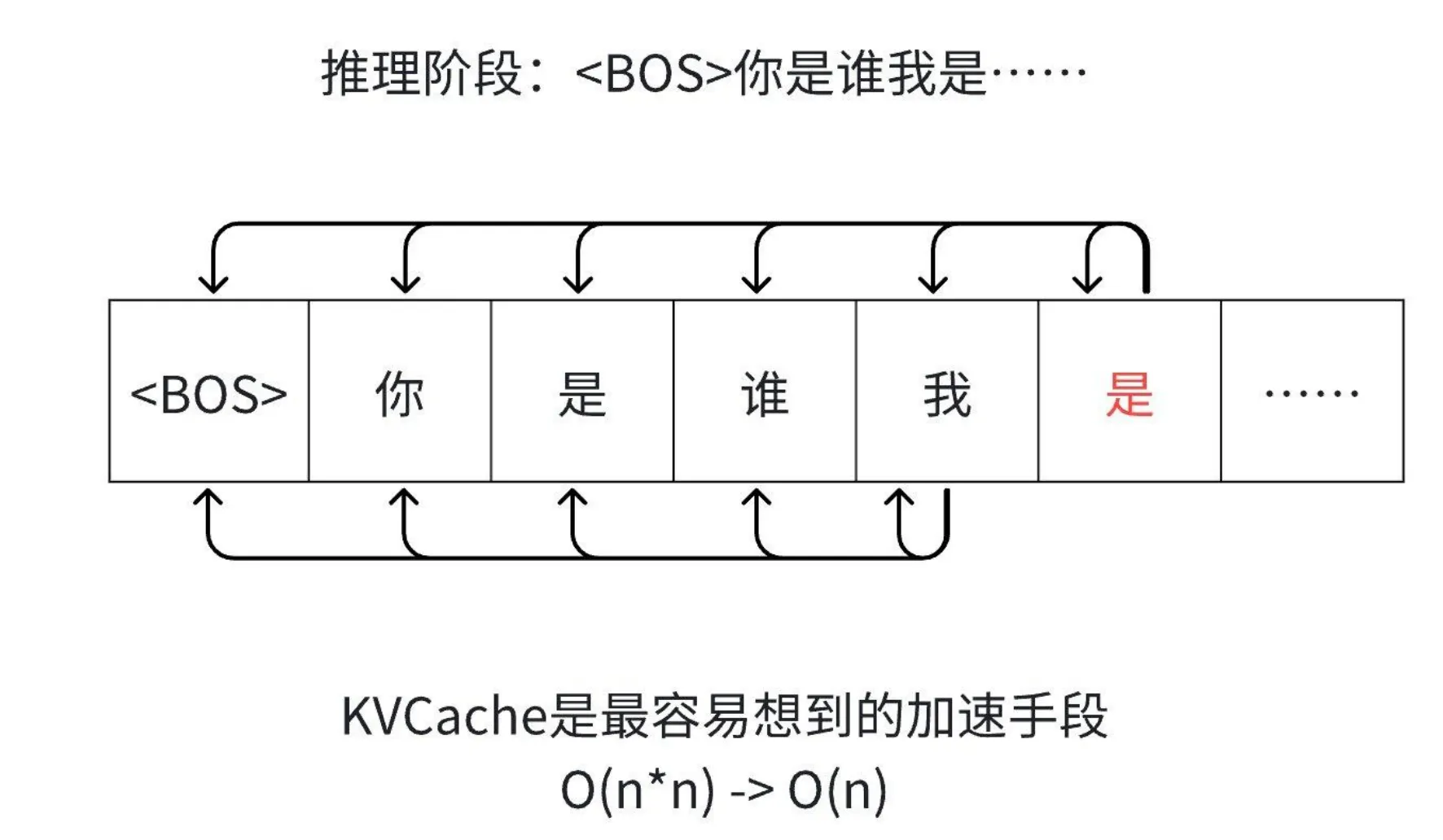
随着序列长度n增加,计算量呈平方级增长,生成速度显著下降。为解决这一问题,KV Cache技术应运而生,核心目标是在推理阶段通过缓存历史计算结果,避免重复计算,降低时间复杂度,提升推理效率。
二、技术原理与核心思想
(一)基本原理
KV Cache的核心是利用缓存机制暂存计算过程中的Key和Value值,供后续重复使用,类似热水器暂存热水。在Transformer中,Query每次针对新生成的Token计算,无需缓存;而Key和Value会被多次使用,因此仅缓存这两个值。生成新Token时,只需计算新Query与缓存的Key和Value的相关性,无需重新计算历史Token的Key和Value。
(二)应用场景
- 推理阶段优化:训练阶段模型通常并行计算整个序列,无需逐个生成Token,因此无需KV Cache;推理阶段逐个生成Token时,KV Cache可显著提升速度。
- Decoder结构专用:Encoder的Self-Attention并行计算,无需缓存;Decoder的Cross-Attention可缓存Encoder输出的Key和Value;主流LLM多采用Decoder-only结构,更适合KV Cache优化。
(三)通俗理解
KV Cache 通俗理解:
- Cache缓存原理:多次使用的东西暂存,下次直接取用(如热水器)。
- 为何只缓存Key和Value?因只有Key和Value需重复使用,Query无需重复使用。
- 仅针对推理阶段优化:因推理阶段逐个生成Token。
三、具体实现与流程
(一)计算过程对比
原始计算过程
每次生成新Token需重新计算所有历史Token的Key和Value,并与新Query计算Attention。例如生成序列“我是你的助手”时,每一步都基于当前所有输入Token计算,计算量随序列长度剧增。
使用KV Cache的计算过程
以输入“你是谁”生成“我是你的助手”为例,第一步生成“我”时缓存Key和Value;第二步生成“是”时,仅计算新Query(基于“你是谁我”),并与缓存的Key和Value及新生成的Key和Value计算,后续步骤复用缓存,仅添加新Key和Value。
(二)代码实现要点
参数与类:在Hugging Face的Transformers库中,通过use_cache=True启用KV Cache,past_key_values表示缓存。DynamicCache类管理缓存,包含两个列表存储各层的Key和Value,形状为[batch_size, num_heads, seq_len, head_dim]。
更新机制:添加新缓存时,在seq_len维度拼接。以下是DynamicCache类的Python实现:
from ast import Dict, Tuple
from typing import Any, List, Optional
from transformers import Cache
import torch
class DynamicCache(Cache):
def __init__(self, num_hidden_layers: Optional[int] = None) -> None:
super().__init__()
self._seen_tokens = 0
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
def update(self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
if len(self.key_cache) <= layer_idx:
for _ in range(len(self.key_cache), layer_idx):
self.key_cache.append([])
self.value_cache.append([])
self.key_cache.append(key_states)
self.value_cache.append(value_states)
elif len(self.key_cache[layer_idx]) == 0:
self.key_cache[layer_idx] = key_states
self.value_cache[layer_idx] = value_states
else:
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
return self.key_cache[layer_idx], self.value_cache[layer_idx]更新机制判断逻辑:
| 条件 | 说明 | 处理方式 |
|---|---|---|
len(self.key_cache) <= layer_idx | 首次遇到该层 | 初始化缓存 |
len(self.key_cache[layer_idx]) == 0 | 层存在但缓存为空 | 直接赋值 |
| 其他 | 层已存在且有缓存 | 拼接新内容 |
四、技术效果与局限性
(一)优化效果
KV Cache通过“空间换时间”将推理阶段的时间复杂度从O(n²)优化至O(n),显著加速长序列生成。
(二)局限性与扩展优化
- 空间占用问题:序列越长,KV Cache占用内存线性增长,可能导致内存不足。可结合
GQA(Group Query Attention)技术,减少缓存的Key和Value头数量,平衡效果与空间。 - 应用场景限制:仅适用于推理阶段和Decoder结构模型,训练阶段无法使用。
五、总结
KV Cache 核心要点总结:
- 以空间换时间,加速推理阶段长序列生成。
- 仅在推理阶段使用,训练阶段并行计算无需缓存。
- 仅适用于Decoder结构:Encoder的Self-Attention并行计算,Decoder的Cross-Attention可缓存Encoder输出,LLM多为Decoder-only结构。
- 空间优化方案:结合GQA技术减少缓存占用。