• BayesA/BayesB:使用 BGLR 包中的 BGLR 函数,选择相应的模型。
• BayesC 和 BayesRR:使用 BGLR 包,通过 BGLR 函数中的 ETA 参数指定模型。
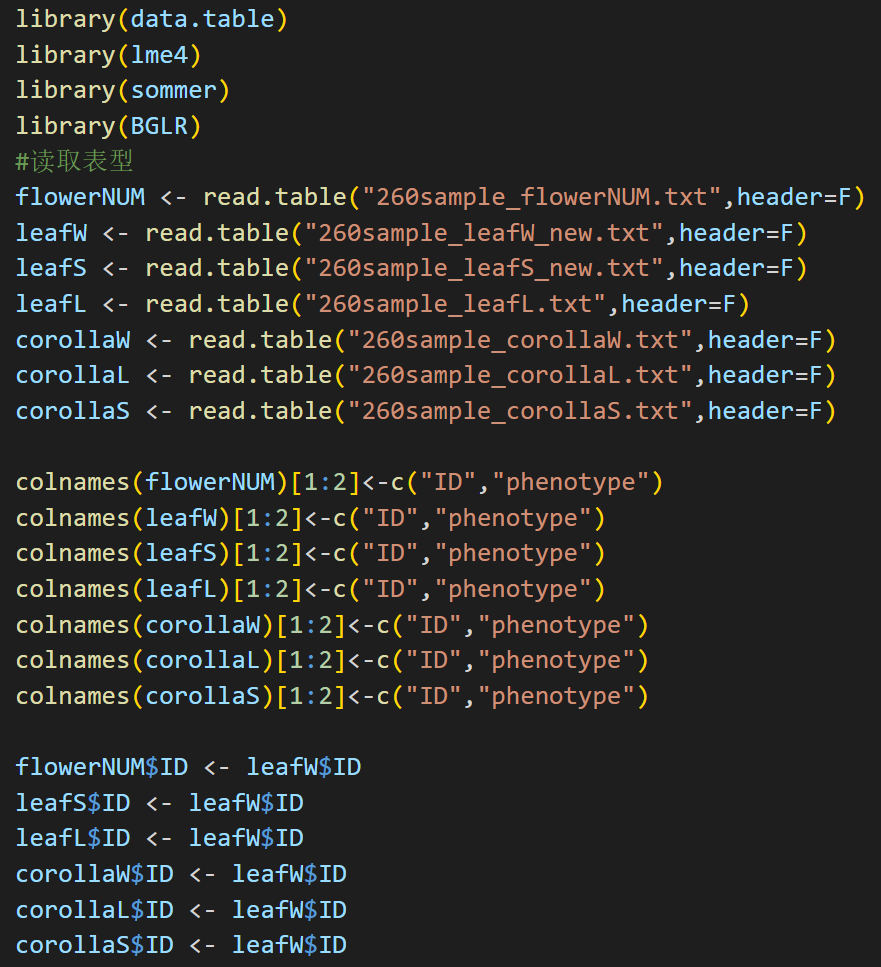
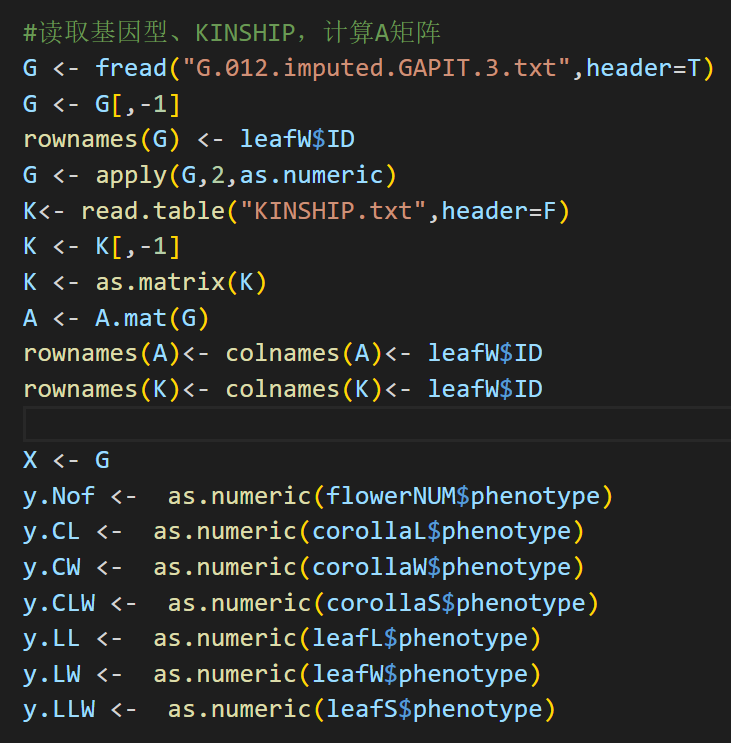
使用BGLR包进行计算:
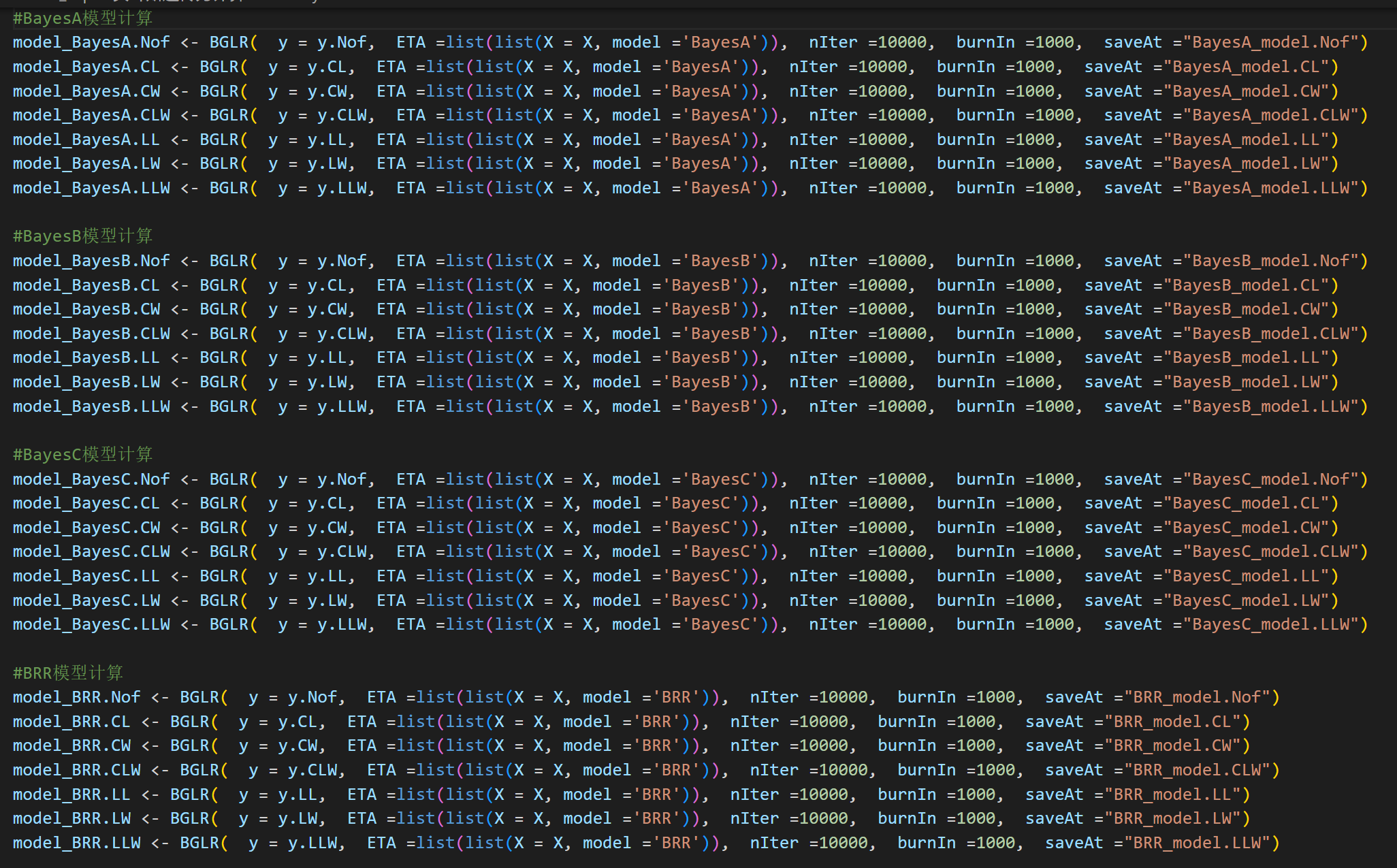
关于模型的参数:
- yHat: 模型预测的响应变量的值(即,预测的表型值)。它表示在给定基因型数据和模型参数下,模型对每个样本的表型值的预测。
- ETA: 一个列表,每个列表项对应于模型中使用的一个ETA(Effect of Trait Architecture)组件。每个ETA组件都包含了以下子项:
- X: 输入的基因型矩阵。
- model: 使用的模型类型(如BayesA、BayesB、GBLUP等)。
- d: 贝叶斯模型中每个标记的方差参数。
- b: 每个标记的效应估计值。
- varE: 环境方差的估计值。它表示响应变量中无法通过基因型数据解释的那部分方差。
- SD.varE: 环境方差估计值的标准差。它提供了关于环境方差估计值的不确定性的度量。
- varU: 如果模型中包括了随机效应(如基因组宽泛的随机效应),则
varU表示这些随机效应的方差估计值。 - SD.varU: 随机效应方差估计值的标准差。它提供了关于随机效应方差估计值的不确定性的度量。
- deviance: 这是模型的偏差度量。偏差越小,模型拟合数据的能力越强。
- fit: 一个列表,包含模型的拟合度量(如偏差、AIC、BIC等)。
- mu: 模型的截距项的估计值。它表示在所有其他变量取零时,响应变量的预期值。
- varB: 一个向量,包含贝叶斯模型中每个标记的方差参数。
- weights: 如果使用了加权回归模型,这个向量包含每个观测值的权重。
saveAt: 一个字符串,表示模型结果保存的路径。
注意,保存路径的文件是一个dat文件,其中记录了每次迭代的结果,可以使用read.tabke()读取后使用
结果计算示例:
varE_samples <- read.table("bayesa_modelvarE.dat", header =FALSE, sep ="\t")
b_samples <- model_bayesa$ETA[[1]]$b
b_samples <-as.numeric(b_samples)
Vg <- rowSums(b_samples^2)/ ncol(b_samples)
Vg_mean <- mean(Vg)
Vg_sd <- sd(Vg)
varE_values <-as.numeric(varE_samples$V1)
Ve_mean <- mean(varE_values)
Ve_sd <- sd(varE_values)
heritability <- Vg /(Vg + varE_values)
str(heritability)