转录组数据量化指标详解
一、前言
在转录组分析中,Reads、Count、RPK、RPKM、TPM、CPM等指标用于量化基因表达。本文结合实际案例,解析各指标的计算公式、计算实例及使用范围,帮助理解其应用逻辑。
二、指标解析
(一)Read
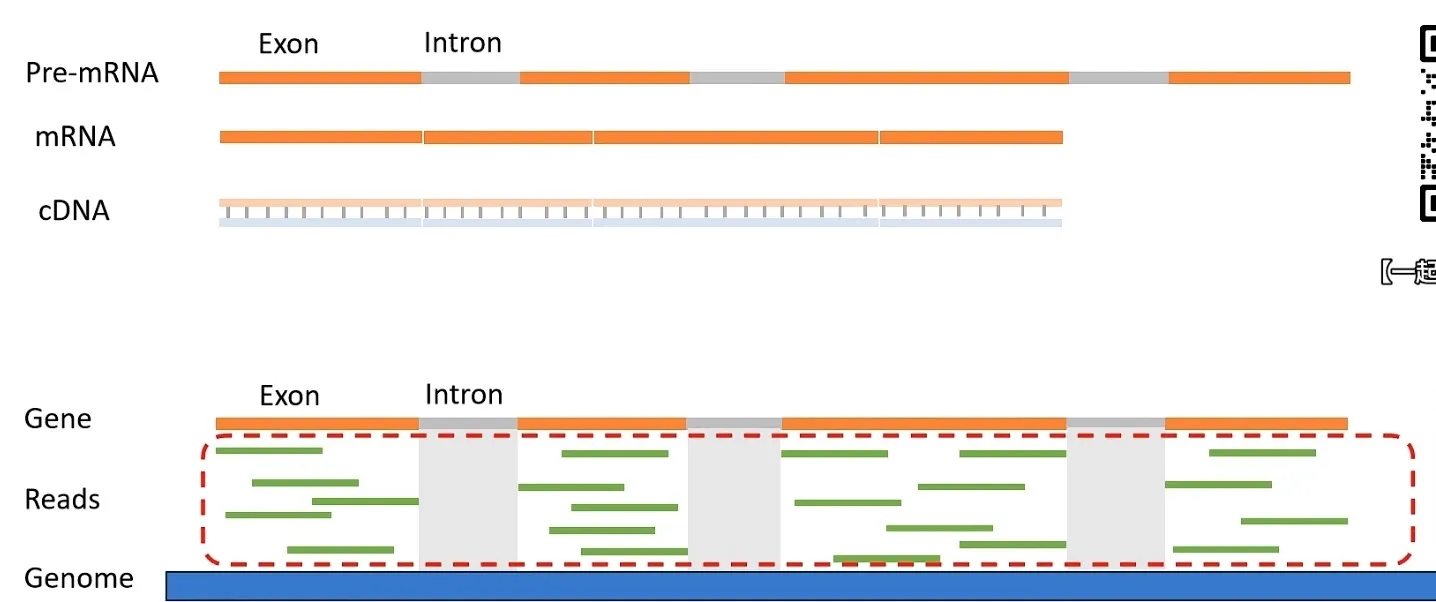
- 定义:在单端测序中,Reads指测序生成的短序列(reads)成功比对到目标基因(或转录本)的数量。如图中绿色短序列,若为单端测序,统计比对到基因外显子区域的这些序列数量,即为对应基因的 Reads 数。
- 使用范围:作为单端测序的原始量化数据,仅反映基因在单端测序中的被检测情况。由于未标准化,其数值易受基因长度(长基因更易获得更多 Reads)和测序深度影响,仅适用于同一样本内的简单比较(如技术重复间的初步观察),无法直接用于跨样本或复杂的表达差异分析。
说人话就是,有多少片段 map 到了基因上边
(二)Count
- 定义:针对双端测序,Count表示比对到目标基因(或转录本)的片段数量。双端测序会产生一对末端序列(reads 对),每成功比对到基因上的一对片段,计为 1 个 Count。如图中若为双端测序模式,统计比对到基因区域的片段对数,即为该基因的 Count 值。
- 使用范围:作为双端测序的原始计数数据,是后续标准化分析(如计算 FPKM、TPM 等)的基础输入。但未标准化的 Count 同样受基因长度和测序深度干扰,不能直接用于跨样本比较或差异分析,需通过 RPKM、TPM 等方法标准化后,才能准确评估基因表达水平。
接下来,看一张图,就全部明白了,但是首先,我们要知道如何定义一个基因的长度
基因长度的定义
| 方法 | 描述 | 适用场景 |
|---|---|---|
| a. 基因最长的转录本长度 | 选取基因所有转录本中长度最长的转录本 | 转录本差异大且最长转录本主导表达的基因 |
| b. 多个转录本长度的平均值 | 计算基因所有转录本长度的平均值 | 转录本表达均衡的基因 |
| c. 非重叠外显子长度之和(L1+L2+L3+L4) | 将基因外显子区域(不含内含子)的非重叠部分长度相加 | 常用方法,聚焦成熟mRNA编码区域 |
| d. 非重叠 CDS 序列长度之和 | 仅计算基因编码蛋白质的 CDS 区域非重叠部分长度总和 | 关注蛋白质编码的表达分析 |
这里我们选择 c 作为一个基因的长度

说人话就是 Counts 就是一个 Gene 的所有 Reads
(三)RPK(Reads Per Kilobase)
\( RPK_i = 10^3 \cdot \frac{n_i}{l_i} \) (\(n_i\)为基因Counts,\(l_i\)为基因长度,单位kb)
实例
| 基因 | Sample1 (counts) | 基因长度 | Sample1 (RPK) |
|---|---|---|---|
| Gene A (2kb) | 8 | 2 kb | \(10^3 \cdot 8/2000 = 4\) |
| Gene B (1kb) | 6 | 1 kb | \(10^3 \cdot 6/1000 = 6\) |
(四)RPKM(Reads Per Kilobase of transcript per Million mapped reads)多用于单端测序
\( RPKM_i = 10^9 \cdot \frac{n_i}{l_i \cdot \sum_j n_j} = 10^6 \cdot \frac{RPK_i}{\sum_j n_j} \) (\(\sum_j n_j\)为样本总Counts)
实例
| 基因 | Sample1 (counts) | Sample2 (counts) | Sample1 (RPKM) | Sample2 (RPKM) |
|---|---|---|---|---|
| Gene A (2kb) | 8 | 16 | \(0.4 \cdot 10^6\) | \(0.1 \cdot 10^6\) |
| Gene B (1kb) | 2 | 64 | \(0.2 \cdot 10^6\) | \(0.8 \cdot 10^6\) |
以Sample1的Gene A为例: \( RPKM_1 = 10^9 \cdot \frac{8}{2000 \cdot (8 + 2)} = 10^6 \cdot \frac{4}{8 + 2} = 0.4 \cdot 10^3 \)
(五)TPM(Transcripts Per Million)
\( TPM_i = 10^6 \cdot \frac{RPK_i}{\sum_j RPK_j} = 10^6 \cdot \frac{n_i/l_i}{\sum_j (n_j/l_j)} \)
实例
| 基因 | Sample1 (counts) | Sample2 (counts) | Sample1 (TPM) | Sample2 (TPM) |
|---|---|---|---|---|
| Gene A (2kb) | 8 | 16 | \(0.667 \cdot 10^6\) | \(0.111 \cdot 10^6\) |
| Gene B (1kb) | 2 | 64 | \(0.333 \cdot 10^6\) | \(0.889 \cdot 10^6\) |
以Sample1的Gene A为例: \( TPM_a = 10^6 \cdot \frac{8/2000}{8/2000 + 2/1000} \approx 0.667 \cdot 10^6 \)
(六)CPM(Counts Per Million)
\( CPM_i = 10^6 \cdot \frac{n_i}{\sum_j n_j} \)
实例
| 基因 | Sample1 (counts) | Sample2 (counts) | Sample1 (CPM) | Sample2 (CPM) |
|---|---|---|---|---|
| Gene A (2kb) | 8 | 16 | \(0.8 \cdot 10^6\) | \(0.2 \cdot 10^6\) |
| Gene B (1kb) | 2 | 64 | \(0.2 \cdot 10^6\) | \(0.8 \cdot 10^6\) |
以Sample1的Gene A为例: \( CPM_a = 10^6 \cdot \frac{8}{8 + 2} = 0.8 \cdot 10^6 \)
三、总结
| 指标 | 计算核心逻辑 | 适用比较场景 |
|---|---|---|
| RPK | 基因长度标准化 | 单样本内基因比较 |
| RPKM | 基因长度+测序深度标准化(单端) | 样本内比较,早期跨样本 |
| TPM | 基因长度+测序深度标准化(全局) | 组内+组间比较,差异分析 |
| CPM | 测序深度标准化 | 组间比较,低表达基因筛选 |
通过理解各指标的计算逻辑与适用范围,结合实际案例分析,可在转录组研究中更精准地选择量化指标,提升分析结果的可靠性。