本文主要阐述采用大疆航拍二维重建后图片进行yolo(以yolov5为例)语义分割模型训练的全过程。
0.前期准备
大疆重建二维图像(results.tif)
1. 图像拆分
由于大疆智图重建后图像整个过于庞大,因此需要整张图像经过分割后再用于训练。
分割代码如下:
import cv2
import numpy as np
import os
input_folder='.'
# 遍历当前目录及所有子目录
for filename in os.listdir(input_folder):
if filename.endswith(('.tif')): # 仅处理图片文件
image_path = os.path.join(input_folder, filename)
image = cv2.imread(image_path)
# 获取图片的尺寸
height, width, channels = image.shape
# 计算每个小块的宽度和高度
block_height = height // 16 # 纵向分割为16块
block_width = width // 12 # 横向分割为12块
# 分割并保存每个小块
for i in range(16): # 纵向分割16块
for j in range(12): # 横向分割12块
# 计算每个小块的位置
y1 = i * block_height
y2 = (i + 1) * block_height
x1 = j * block_width
x2 = (j + 1) * block_width
# 从原图中提取小块
block = image[y1:y2, x1:x2]
# 显示每个小块
# cv2.imshow(f"Block_{i + 1}_{j + 1}", block)
# 保存每个小块
cv2.imwrite(f"{image_path}_{i + 1}_{j + 1}.jpg", block)
# 等待按键后关闭所有窗口
cv2.waitKey(0)
cv2.destroyAllWindows()该代码主要用于将当前目录下的tif文件拆分为等大的16*12个矩形块并以jpg格式切分行和列坐标进行命名保存。通过调整input_folder及参数即可改变分割的大小及输入图像位置。(当然可能大疆智图也可以实现该功能)
2. 图像筛选(可跳过)
由于大疆重建时有部分区域没有完成重建,因此可能需要手动删去效果不好的图片数据。
3. 使用labelme打标签(目标检测使用labelimg更为方便,对于前后景差距比较明显的也可以使用SAM相关的打标签工具来打标签)
安装labelme:在cmd中激活我们使用的python环境,然后使用pip命令安装labelme,命令如下:
pip install labelme==3.16.7注意:如果安装最新版本的 labelme,就无须指定版本号(3.16.7就是版本号)
打开labelme:在cmd中激活我们使用的python环境,然后使用下面的命令,就可以打开labelme软件:
labelme
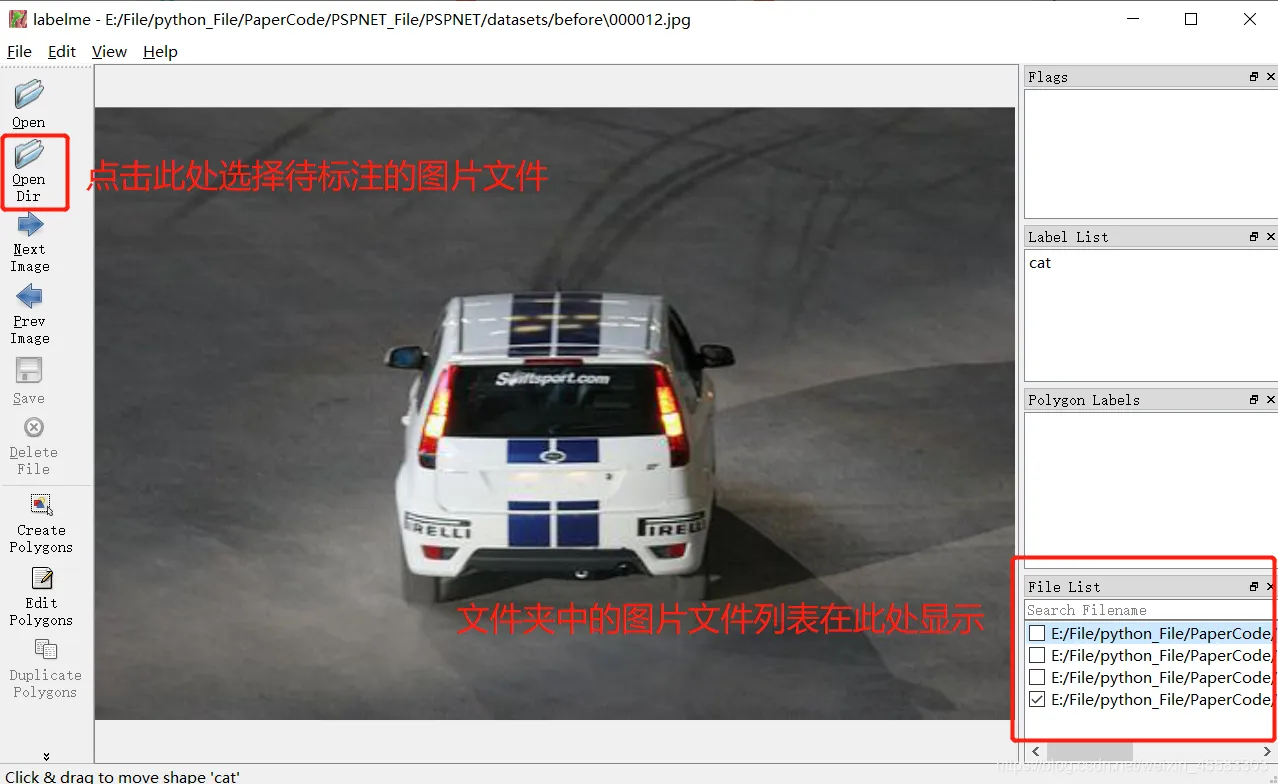
使用labelme对数据集进行标注:第一步:打开我们要标注图片的文件夹。
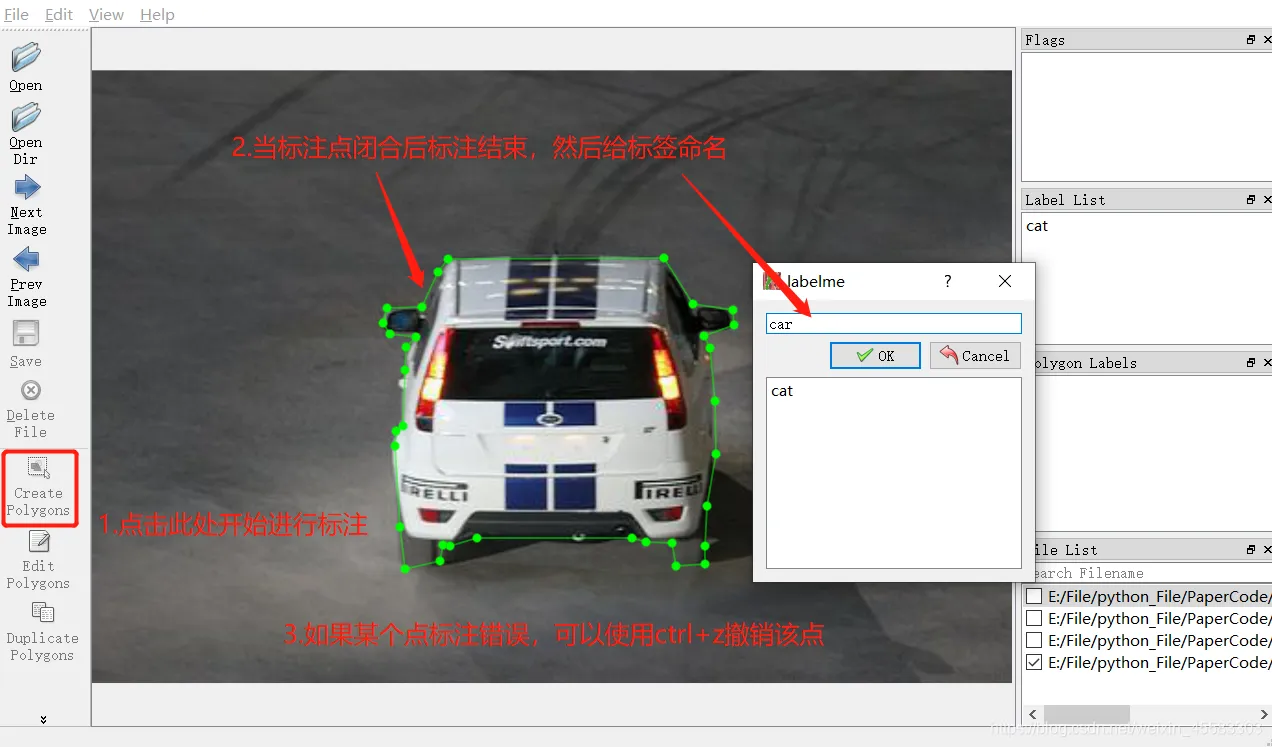
第二步:选择多边形标注,然后对图片进行标注,通过点选来绘制多边形。
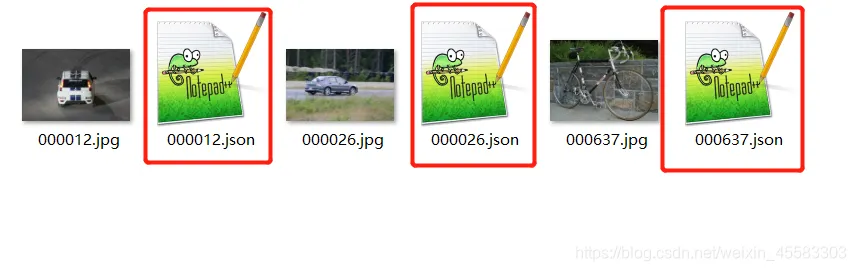
如下图所示,标注完的图片会在相应目录中产生一个.json文件存储所绘制标签的坐标等信息。依次标注完所有数据即可。
原文链接:https://blog.csdn.net/weixin_45583303/article/details/116009777
4. 数据集格式转换
由于数据集主要采用VOC格式进行标注,标注文件通常以XML格式存储,且遵循Pascal VOC数据集的标准格式。每个标注文件描述了图像中的目标信息,包括目标的类别、边界框位置等信息。
然而,YOLO目标检测模型使用的是与VOC格式不同的标注格式。在YOLO中,标注信息存储在以.txt为后缀的文本文件中,每个文本文件与图像文件一一对应。YOLO的标注文件结构较为简单,主要包含每个目标物体的类别索引以及边界框的坐标信息。具体来说,每一行代表一个物体,包含以下内容:
(1) 类别索引:物体在类别列表中的索引,通常从0开始。
(2) 边界框中心坐标(x_center, y_center):目标物体的边界框中心的相对位置(以图像宽度和高度的比例表示)。
(3) 边界框宽度(width)和高度(height):目标物体的边界框的宽度和高度,也是以图像尺寸的比例表示。
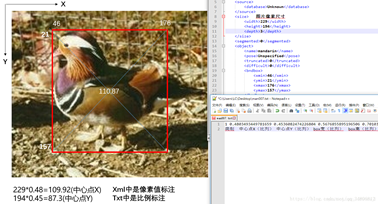
COCO格式中每一行代表一个目标物体,其中第一个数字是类别索引,后面的四个数字是边界框的坐标信息。
因此,为了能够使用YOLO进行目标检测,必须将原始的VOC格式XML标注文件转换成YOLO所需要的TXT格式。这一过程需要对每个XML文件进行解析,提取出其中的目标类别和边界框信息,并按YOLO格式保存为TXT文件。
为了实现这一转换过程,可以编写一个Python脚本.
在脚本运行前建议将标注完的数据集文件夹按照以下目录进行划分:
E:.
├─img #存储图片
├─json #存储对应json文件
├─out #存储转换并整理后的数据集文件
└─txt #存储转换后的txt文件import json
import os
from tqdm import tqdm
"""最终可以使用的版本"""
def convert_label(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
path = os.path.join(json_dir, json_path)
print(f"loaf:{json_path}")
with open(path, 'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path, 'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
json_dir = 'shuguan1/a1/json'
save_dir = 'shuguan1/a1/txt'
classes = 'grass,other tree,tree'
convert_label(json_dir, save_dir, classes)import shutil
import random
import os
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def split(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir)
mkdir(labels_dir)
mkdir(img_train_path)
mkdir(img_test_path)
mkdir(img_val_path)
mkdir(label_train_path)
mkdir(label_test_path)
mkdir(label_val_path)
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
image_dir = 'shuguan1/a1/img'
txt_dir = 'shuguan1/a1//txt'
save_dir = 'shuguan1/a1/out'
split(image_dir, txt_dir, save_dir)
通过以上俩个脚本即可将coco格式数据集转化为YOLO格式数据集并按训练格式进行划分,训练格式如下:
E:.
├─images
│ ├─test
│ ├─train
│ └─val
└─labels
├─test
├─train
└─val5. 编写datasets.yaml文件
按照yolo示例中的yaml文件编辑即可,示例如下:
train: ./data/shuguan1/a2/out/images/train # 训练集图像路径
val: ./data/shuguan1/a2/out/images/val # 测试集图像路径 (可选)
test: ./data/shuguan1/a2/out/images/test
# 类别定义
nc: 3 # 类别数目,例如:2类,"person", "car"
names: ['grass','other tree','tree'] # 类别名称
按照实际情况进行相应修改即可。
后续将根据需要看是否将该过程封装为exe或docker。